
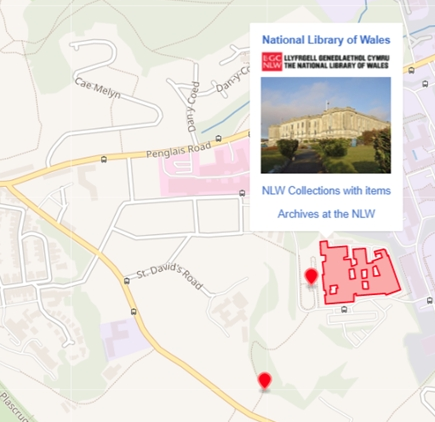
Introduction: This blog post describes how the National Library of Wales makes us of Wikidata for enriching their collections. It especially showcases new features for visualizing items on a map, including a clustering service, the support of polygons and multipolygons. It also shows how polygons like the shapes of buildings can be imported from OpenStreetMap into Wikidata, which is a great example for re-using already existing information.



